In a world characterized by the increasing availability of data, classic Marketing Mix Modeling based on national modeling falls short of marketers’ expectations when it comes to the provision of granular insights necessary for data-driven decision-making.
Thus, there is a real need today for advanced modeling techniques that can empower marketers to harness insights from Marketing Mix Models and embrace a contemporary approach. In particular, Regional Modeling, also known as Pooled Regression, is becoming increasingly popular in this new paradigm.
With access to granular data points like Regions/DMAs, Stores, and even consumer segments, cross-sectional or regional modeling can provide marketers with detailed insight into consumer behavior specific to the region or store location.
What is Pooled Regression?
Pooled Regression is usually carried out when we have available time series of cross-sections i.e., data that has observations over time for several different groups or cross-sections. A cross-section could be a region, store, DMA, consumer segment, etc.
Fixed Effect estimators can be used to derive unbiased and consistent estimates of the model coefficients. However random effects could be more appropriate when time constant attributes are present.
Benefits of Using Pooled Regression
Pooled Regression increases the number of data points and the model dimensions resulting in higher accuracy. With Pooled Regression, we can measure different factors at the store/region level and aggregate results at the national level. The deployment of Pooled Regression allows to:
• Increase data size and the confidence in all measures (T-stat): Often, the most practical way to decrease the margin of error is to increase the sample size. This means that the more observations we have, the narrower the interval around the sample statistic is. Thus, using Pooled Regression to increase the size of available data will allow obtaining a more precise estimate of the impact of media and marketing on sales.
• Use shorter modeling period: Typically, time-series regression models need a minimum history of data to yield robust results (preferably 2 to 3 years’ worth of weekly data). However, if we have less than 2 years of data but this is available for multiple groups, like stores or similar products, then one can build a “pooled” model by combining time-series observations across these several groups to increase the number of data points and get results at a more disaggregated level. Hence, Pooled Regression allows using shorter modeling periods busting the myth that Marketing Mix Models are resource-intensive and data-heavy.
• Decomposing the effect of variables by region/unit/store: Pooled Regression provides a detailed understanding of the model by measuring the impact of variables at the cross-section level, e.g., region, store
customer segment. We can for example pinpoint the impact of Online Media spending on the customer by segment (loyal customers, switching, new to the category, etc.) or by region or by any other chosen cross-section.
• Test New Marketing Strategies: Pooled regression allows adding the regional dimension to the mix and use panel data. This additional dimensionality could be leveraged to improve A/B testing. Using pooled MMM models in this context allows to measure response in the test region and assess performance in comparison to the control region. This benefit is valuable to brands aiming to test a marketing or advertising tactic at a small scale ahead of generalization.
It is because of these benefits that measurement professionals opt for Pooled Regression when running Marketing Mix Modeling projects. However, relying on pooled regression does not come without its own hurdles.
Challenges of Implementing Pooled Regression
Pooled Regression can be difficult to implement because the process of collecting and transforming more granular data can be time-consuming and costly. The granularity of the data collected will affect how long this takes as well as who needs to get involved in the process in order to ensure high-quality data. It is for that reason that some advertisers refrain from using it without a specialist Marketing Mix Modeling Software that would ease up this stage.
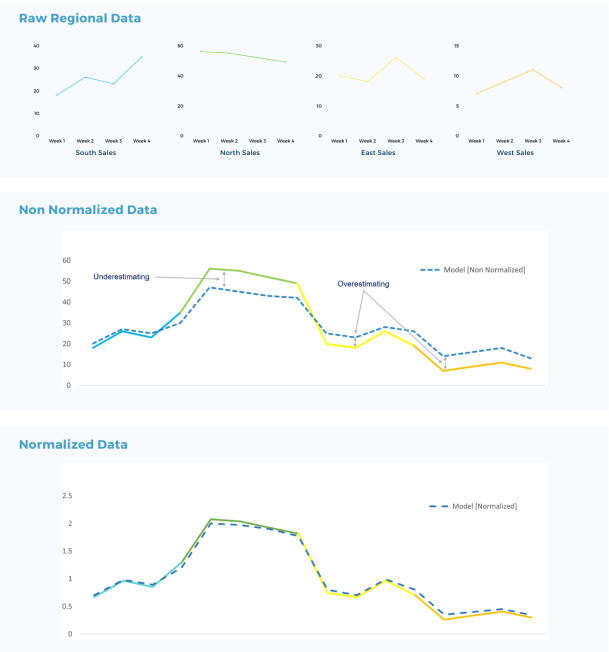
Another factor to take into consideration is the difference in the means across regions. Pooled Regression efficiency is challenged when attempting to measure the impact of regions that have sales positioned far from the regional average.
This common challenge results in:
• Overestimating the impact in the regions that have lower sales than the average.
• Underestimating the impact in the regions that have higher sales than the average.
To circumvent this issue, data need to be normalized as illustrated below:
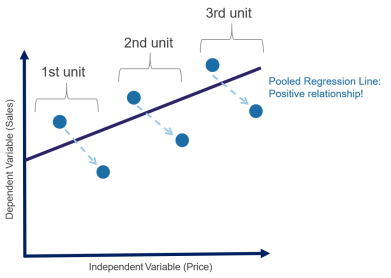
Furthermore, using Pooled Regression without applying the required transformations could result in obtaining counterintuitive results. For example, in the figure featured below, if we look at each cross-section separately (unit), the Sales/Price relationship is negative. However, if we pool the data and estimate the resulting equation, the impact is positive! Hence transforming the data prior to pooling is a must.
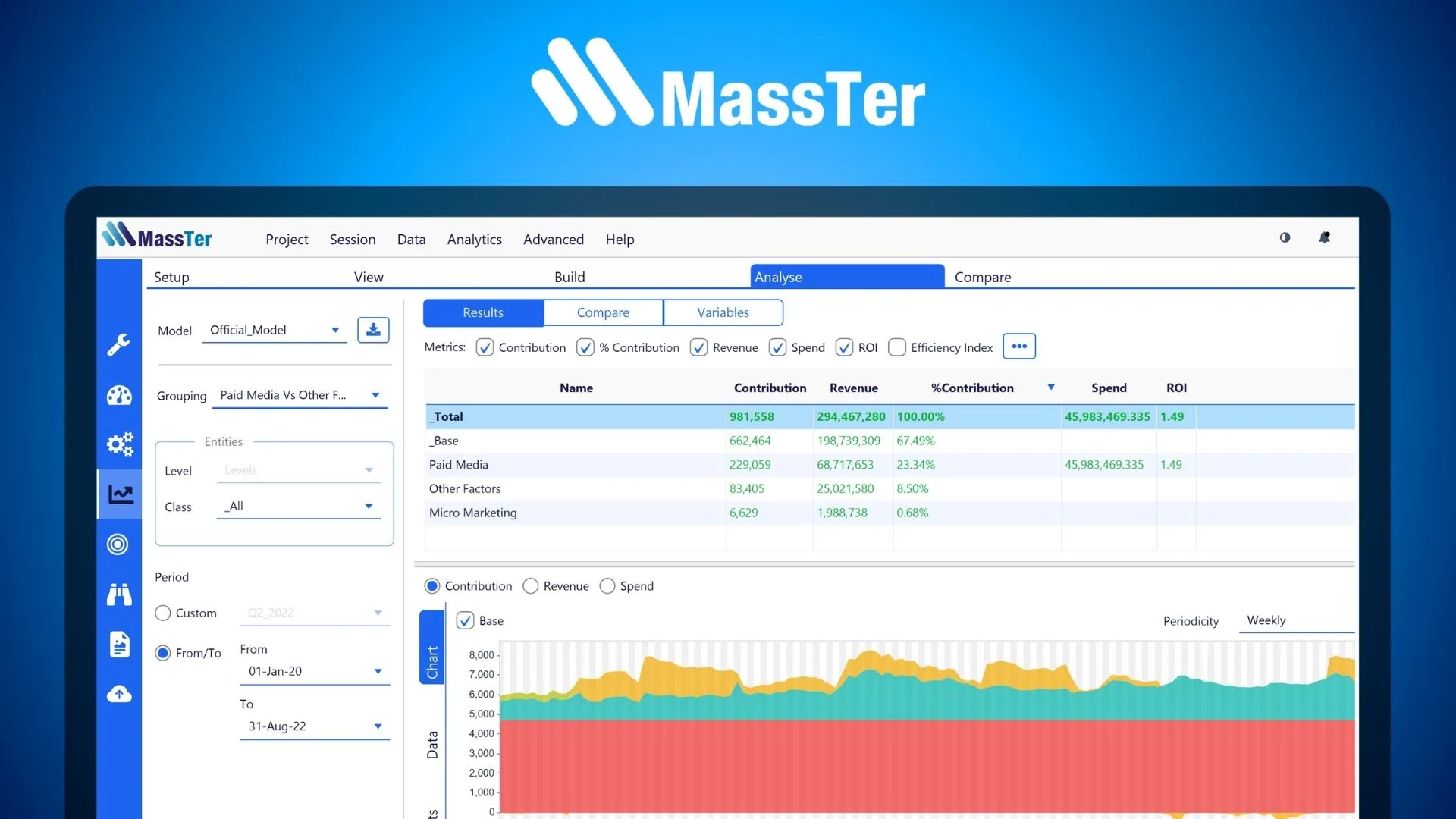
How We Use Pooled Regression at MASS Analytics?
As shown at the start of this article, traditional Marketing Mix Modeling is often performed at the national/aggregate level. This does not allow to detect the impact of a certain media activity or channel on a region/cross-section, especially when that region represents a small percentage of total sales.
Our end-to-end Marketing Mix Modeling software MassTer not only allows to easily estimate a Pooled Model while automatically dealing with data normalization but also offers the user the flexibility to split national variables into regions to find out whether consumers react differently to media and marketing. The result is a granular model that provides actionable Media Mix insights at the regional level.
These regional results are then fueled seamlessly into our optimizer allowing to adjust media investments while accounting for both regional and national effects, resulting in a better representation of the ground truth.
MASS Analytics promotes a contemporary Marketing Mix Modeling approach delivering faster, automated, and dynamic models powered by Machine Learning to accurately measure the impact of media and marketing in a complex and interactive media landscape.
To find out how our experts and tools can help you optimize your marketing ROI using Pooled Regression technique, book a demo with us here.